


















Lexi
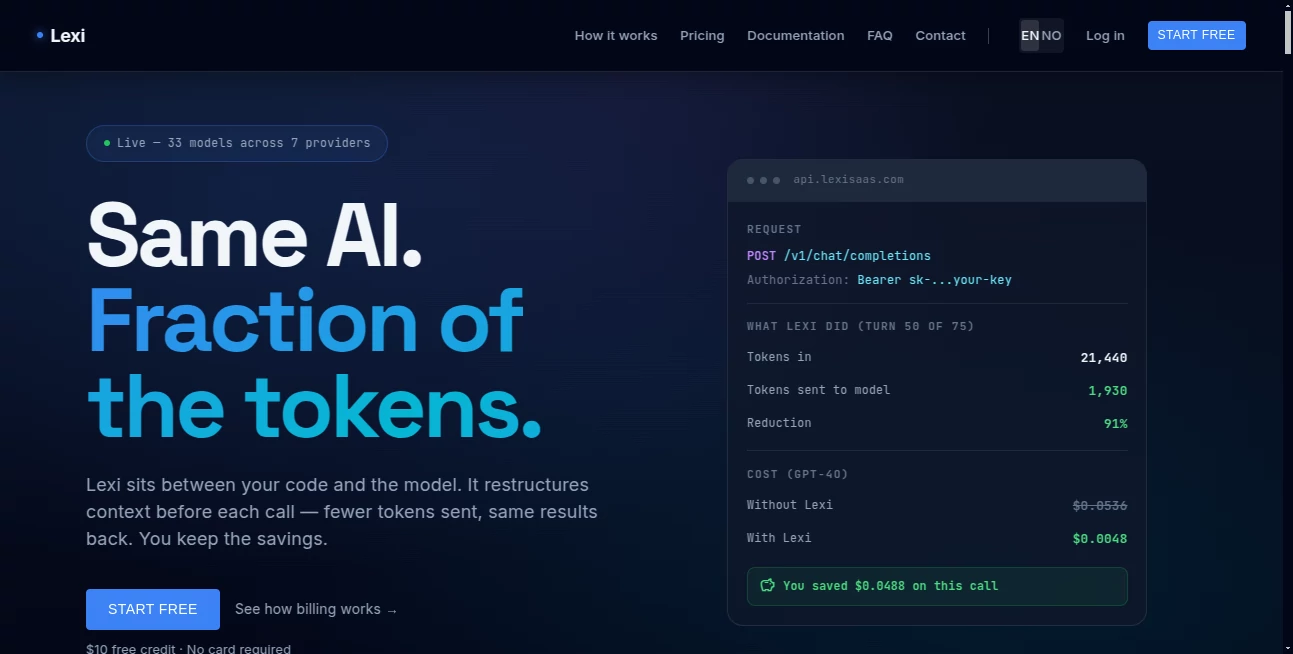
What is Lexi?
Running AI applications at scale can become expensive surprisingly fast. Every new message in a conversation increases the number of tokens sent to the model, driving costs higher with each request. This platform approaches the problem differently by optimizing conversation context before it reaches leading AI providers, allowing developers to reduce token usage while maintaining response quality.
Instead of requiring teams to redesign prompts or rewrite applications, it works as a drop-in API layer between existing software and popular AI models. Integration takes only a small configuration change, making it attractive for startups, SaaS companies, AI agents, customer support systems, research assistants, and enterprise applications that rely on long conversations.
One of its strongest advantages is the proprietary optimization engine that restructures context rather than simply trimming or summarizing it. As conversations grow longer, the platform keeps request sizes predictable, helping organizations lower infrastructure expenses while preserving important facts and decisions throughout the session.
Key Features
User Interface
The platform focuses on a developer-friendly experience. Users receive a single API endpoint compatible with multiple AI providers, making migration quick and straightforward. Detailed request headers display token usage, savings, costs, and optimization statistics, giving engineering teams complete visibility into every API call.
Accuracy & Performance
The optimization engine restructures conversation history instead of removing valuable information. This allows lengthy AI conversations to remain coherent while dramatically reducing the number of tokens sent to the underlying language model. In benchmark testing, long conversations achieved significant token reductions with almost no noticeable impact on practical response quality.
Capabilities
- Supports multiple leading AI providers through one endpoint.
- Reduces token consumption in long conversations.
- Works with streaming responses.
- Supports tool calling.
- Maintains structured outputs.
- Keeps important facts available across lengthy sessions.
- Provides transparent cost reporting.
- Requires minimal code changes for integration.
- Scales automatically as API usage increases.
Security & Privacy
Security has been designed as a core component rather than an afterthought. Conversation data is encrypted while being processed, sensitive information is protected, and provider credentials are not permanently stored. The service also follows a minimal-data collection approach, making it suitable for organizations with strict privacy requirements.
Use Cases
- AI coding assistants handling long development sessions.
- Customer support chatbots with extensive conversation histories.
- Research assistants processing complex multi-step tasks.
- Enterprise AI platforms serving thousands of users.
- Document analysis applications.
- Workflow automation powered by large language models.
- AI SaaS products seeking to reduce infrastructure costs.
- Teams building production-ready AI agents.
Pros and Cons
Pros
- Very easy to integrate into existing AI applications.
- Supports several major AI providers.
- Helps reduce API expenses for long conversations.
- Transparent reporting of savings and token usage.
- Maintains conversation quality through intelligent context restructuring.
- Works with modern API features such as streaming and tool calls.
Cons
- Savings depend on conversation length and workload.
- Most benefits appear in applications with frequent multi-turn interactions.
- Developers still need API-based applications to take advantage of the service.
Pricing Plans
The service offers free credits for new users, allowing developers to test the platform without an upfront payment. Instead of charging a fixed optimization fee, pricing is based on the savings generated. When optimization produces savings, the platform keeps a percentage while users retain the majority of the reduction. If no savings are achieved, there is no additional optimization fee beyond the normal provider cost.
How to Use Lexi
Getting started is remarkably straightforward. Create an account, obtain an API key, update the base URL used by your existing AI SDK, and begin sending requests through the optimized endpoint. The request and response formats remain familiar, allowing developers to continue using their preferred models with minimal changes. Cost savings and optimization metrics are automatically included with every request.
Comparison with Similar Tools
Unlike traditional AI gateways that primarily route requests or manage authentication, this platform actively restructures conversation context before it reaches the model. Many proxy services focus on monitoring or rate limiting, whereas this solution emphasizes reducing token usage while preserving important conversational details. It is especially valuable for applications that rely on long-running AI sessions where token growth typically becomes the largest operating expense.
Conclusion
For development teams building AI-powered products, managing API costs is becoming just as important as improving model quality. This solution introduces a practical way to control expenses without forcing major architectural changes or sacrificing user experience. Its compatibility with multiple AI providers, simple integration process, transparent billing model, and intelligent context optimization make it a compelling option for modern AI applications that need both performance and predictable operating costs.
Frequently Asked Questions (FAQ)
What problem does this platform solve?
It reduces token usage during long AI conversations, helping developers lower API costs while maintaining high-quality responses.
Does it work with multiple AI providers?
Yes. It supports several major language model providers through a unified API endpoint.
Is integration difficult?
No. Most projects only need to update their API endpoint configuration while keeping existing application logic unchanged.
Can it be used in production applications?
Yes. The platform is designed for production workloads, including AI agents, enterprise software, research tools, and customer support systems.
Is there a free plan?
New users receive free credits to evaluate the service before paying for ongoing usage.
AI DevOps Assistant , AI API Design , AI Developer Tools , Large Language Models (LLMs) .
These classifications represent its core capabilities and areas of application. For related tools, explore the linked categories above.

Lexi Alternatives Product

git-lrc

Project Mela

Luma AI

Lovable APP

Defapi

Firefox

AgentOne

Geekflare AI

Where Is Thi…
