


















Turbopuffer
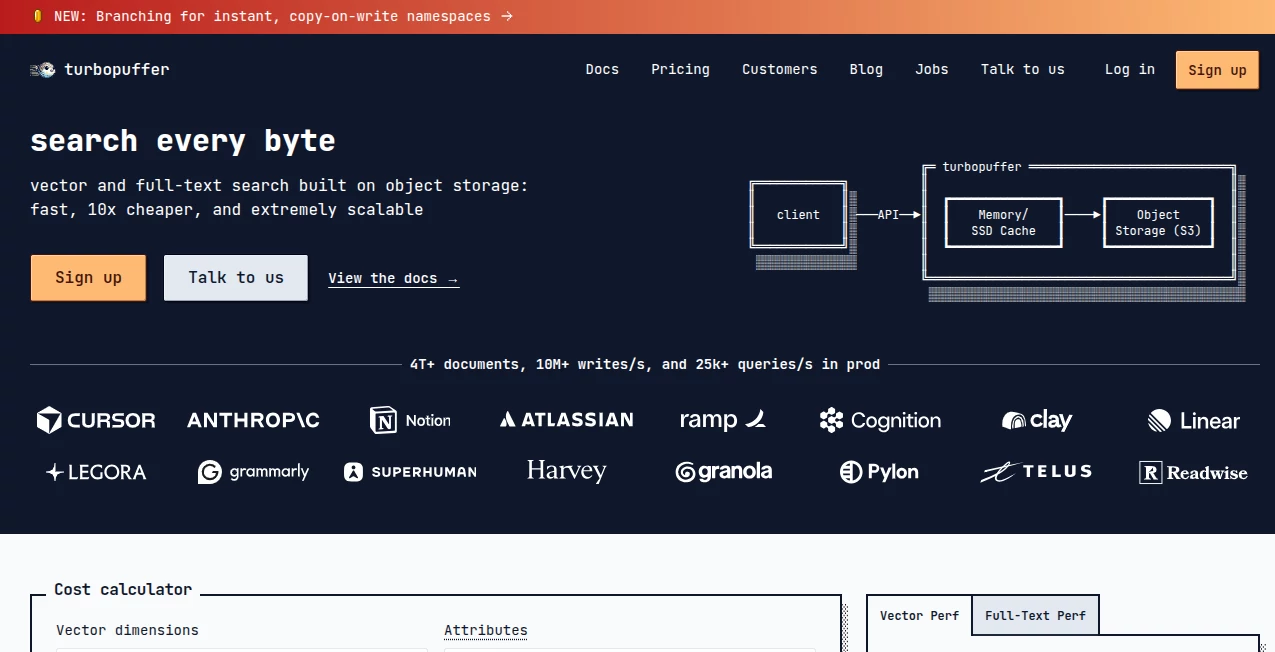
What is Turbopuffer?
Modern applications generate massive amounts of unstructured data—documents, embeddings, logs, and semantic vectors. Traditional databases struggle to keep up with this shift, especially when real-time search and scalability are required at the same time.
This platform is designed to solve exactly that problem. It introduces a serverless approach to vector storage and retrieval, allowing developers to build fast, intelligent search systems without worrying about infrastructure complexity. Whether you're working on AI applications, semantic search, or recommendation systems, it provides a flexible foundation that scales effortlessly.
Key Features
User Interface
The experience is intentionally developer-first, focusing on simplicity and speed. Instead of complex database management, users interact through clean APIs that are easy to integrate into existing systems. The setup process is minimal, making it accessible even for small teams.
Accuracy & Performance
The system is optimized for high-dimensional vector search, delivering low-latency results even at large scale. By combining object storage architecture with advanced indexing techniques, it ensures efficient retrieval without compromising accuracy.
Capabilities
- Semantic vector search across large datasets
- Hybrid search combining keyword and embeddings
- Scalable storage using cloud-native architecture
- Real-time indexing and querying
- Integration with modern AI and LLM pipelines
Security & Privacy
Data security is handled through cloud-grade infrastructure practices. Access control mechanisms and isolated environments help ensure that sensitive information remains protected. The architecture is designed to minimize unnecessary data exposure while maintaining performance.
Use Cases
- Building AI-powered search engines for applications
- Enhancing recommendation systems with semantic understanding
- Storing and querying embeddings from LLM applications
- Powering chatbots with contextual memory retrieval
- Analyzing large-scale unstructured datasets
Pros and Cons
Pros
- Highly scalable serverless architecture
- Fast semantic search performance
- Simple integration for developers
- Optimized for AI-native workflows
Cons
- May require technical knowledge for setup
- Advanced features may feel complex for beginners
- Ecosystem still evolving compared to older databases
Pricing Plans
The pricing model is typically usage-based, allowing teams to pay according to storage and query volume. This makes it suitable for both early-stage startups and large-scale production systems. For enterprise needs, custom arrangements may be available depending on workload and scale.
How to Use Turbopuffer
To get started, developers typically connect their application through an API key and define vector collections. After setting up the schema, embeddings can be inserted directly into the system. Queries can then be executed using similarity search or hybrid search modes.
Most integrations follow a simple workflow: generate embeddings → store vectors → query using semantic similarity → return ranked results. This makes it especially powerful for AI-driven applications.
Comparison with Similar Tools
Compared to traditional vector databases, this solution takes a more cloud-native approach. Instead of relying heavily on fixed infrastructure, it leverages scalable storage systems to handle large datasets efficiently.
While some competitors focus primarily on on-premise or tightly managed environments, this platform emphasizes flexibility, making it easier to scale without operational overhead. It is particularly strong for teams building modern AI applications where speed and elasticity matter more than rigid database control.
Conclusion
For developers and companies building next-generation AI systems, this platform offers a compelling balance between simplicity and power. It removes much of the complexity traditionally associated with vector databases and replaces it with a scalable, developer-friendly approach. As AI applications continue to grow, tools like this become increasingly important in building responsive and intelligent systems.
Frequently Asked Questions (FAQ)
-
Is it suitable for beginners?
It is more suited for developers, but the API-based approach keeps integration straightforward. -
Can it handle large-scale datasets?
Yes, it is designed for high scalability and performance at production level. -
Does it support AI applications?
Yes, it is commonly used in LLM pipelines, semantic search, and recommendation systems. -
Is infrastructure management required?
No, it follows a serverless model that reduces operational overhead.
AI Data Mining , AI Developer Tools , AI Search Engine , Code & IT .
These classifications represent its core capabilities and areas of application. For related tools, explore the linked categories above.

Turbopuffer Alternatives Product

The CAD Hub

freellm

Defapi

Reverse Vide…

Reverse Imag…

Velokey

Tate-A-Tate

Photo Locati…

Luma AI
