🧠 AI Quiz
Think you really understand Artificial Intelligence?
Test yourself and see how well you know the world of AI.
Answer AI-related questions, compete with other users, and prove that
you’re among the best when it comes to AI knowledge.
Reach the top of our leaderboard.


















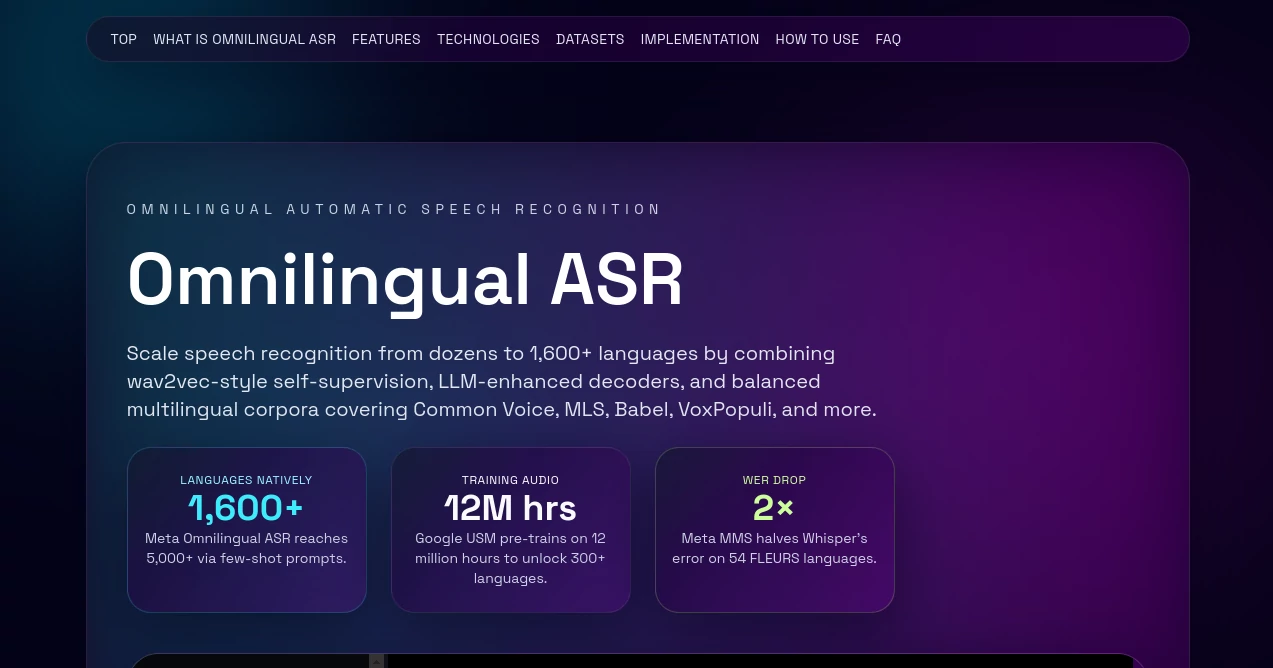
Omnilingual ASR
Universal Speech Recognition for Every Tongue
What is Omnilingual ASR?
Omnilingual ASR breaks down barriers in voice tech, letting a single setup handle whispers in over a thousand languages without missing a beat. Picture feeding it audio from bustling markets in Mumbai or quiet chats in rural villages—out comes text that's spot-on and ready to use. It's the kind of leap that has developers buzzing, turning what used to be a patchwork of tools into one seamless flow for anyone building global apps.
Introduction
Omnilingual ASR hit the scene a few years back, born from a push to make voice tools work for everyone, not just the big languages like English or Mandarin. A team of researchers, drawing from heavy hitters like Whisper and MMS, stitched together massive audio troves to train models that don't play favorites. What kicked off as experiments in shared sound patterns has grown into a powerhouse, with folks from indie devs to big corps sharing stories of how it unlocked doors in places where tech felt out of reach. Today, it's all about that one-model-fits-all vibe, saving headaches and cash while opening up wild possibilities for cross-border projects.
Key Features
User Interface
Getting hands-on feels straightforward, with playgrounds on spots like Hugging Face where you drop audio files and pick languages without digging through code. Dashboards in cloud setups keep it visual—progress bars tick along as it chews through clips, spitting out transcripts with handy highlights for tweaks. No steep walls; even if you're not a coder, the demos guide you through uploads and previews like a friendly walkthrough.
Accuracy & Performance
It shines by slashing error rates, often cutting word slip-ups in half compared to older setups, especially in tricky low-data tongues where others stumble. Handles hefty loads from millions of hours of training, so even mixed accents or noisy clips come out clear, with low delays that keep real chats flowing. Users note how it holds steady across devices, from laptops to edge setups, without the usual dips in tough spots.
Capabilities
From spotting who's talking in a group to flipping speech into other languages on the fly, it packs a punch with encoders that share tricks across borders. Extend it to new dialects with just a smattering of samples, or hook it into streams for live captions. Open checkpoints let you fine-tune for niches, while cloud ties add bells like analytics, making it a Swiss Army knife for voice-driven builds.
Security & Privacy
Open bits run under loose licenses that let you tweak and own your tweaks, with cloud paths locking data tight per provider rules—no sneaky shares without your nod. It flags shaky outputs for double-checks, keeping sensitive talks safe, and wipes temps quick to ease worries in regulated fields like health or finance.
Use Cases
Global teams use it for call logs that catch every dialect in customer huddles, turning raw audio into searchable gold. Content creators slap captions on videos that reach far-flung fans, while educators build tools for kids learning in their home tongues. Non-profits tap it for field recordings in remote areas, bridging gaps where pros can't tread.
Pros and Cons
Pros:
- Covers a wild array of languages in one go, slashing setup hassles.
- Beats rivals on error cuts for overlooked dialects.
- Few-sample stretches make it nimble for fresh needs.
- Mix of open and cloud keeps costs flexible.
Cons:
- Can hallucinate on fuzzy inputs, needing watchdogs.
- Spotty on ultra-rare accents without extra tuning.
- Cloud fees stack up for heavy streaming.
- Benchmarks vary, so test your slice first.
Pricing Plans
Open-source cores like MMS come free for grabs, with tweaks on your dime for hosting. Cloud arms from Google or Azure run pay-per-use, often pennies per minute for basics, scaling to enterprise bundles around hundreds monthly for high-volume flows. Trials let you dip in without upfront hits, and yearly locks on APIs trim the tab for steady runners.
How to Use Omnilingual ASR
Pick your base—grab a checkpoint from Hugging Face for local runs or sign into a cloud console. Feed audio clips, tag languages if mixed, and hit process to watch transcripts roll. Fine-tune with your samples via simple scripts, integrate into apps with SDK hooks, and monitor outputs for confidence dips. Iterate with feedback loops to sharpen it for your crowd.
Comparison with Similar Tools
Against Whisper's tidy 99-language net, it sprawls wider but trades some polish for reach. MMS kin feel like siblings, yet this edges on few-shot tricks; cloud giants like Google pack enterprise shine but lock you in. It wins for open tinkerers chasing global nets over boutique fits.
Conclusion
Omnilingual ASR flips voice tech from elite club to open invite, weaving a web where every accent finds a home. It nudges creators toward bolder builds, proving that smarts can span divides without breaking stride. As chats go borderless, this setup stands ready, turning echoes into echoes heard worldwide.
Frequently Asked Questions (FAQ)
What's the edge over plain multilingual setups?
It shares sound smarts across thousands, dodging per-tongue rebuilds.
How spot-on is it for rare dialects?
Strong cuts on errors, but shines brighter with a dash of local audio.
Does it catch who said what in groups?
Yep, diarization hooks split speakers clean in the mix.
Can it flip to other languages?
Built-in paths turn talk to text and tweak to new tongues.
Live streams a go?
Chunked modes keep it rolling real-time without skips.
AI Transcriber , AI Speech to Text , AI Speech Recognition , AI Voice Assistants .
These classifications represent its core capabilities and areas of application. For related tools, explore the linked categories above.
Omnilingual ASR details
This tool is no longer available on submitaitools.org; find alternatives on Alternative to Omnilingual ASR.
Pricing
- Free
Apps
- Web Tools
Categories

Omnilingual ASR Alternatives Product

Sourcetable

NepVox

WhispriNote

ModelsLab

vo4 ai

Maestra

TurboScribe

Models by Ha…

PDF to MD
